

.png)
Why can't institutions just take their survey data, plug it into ChatGPT or similar, and call it done?
It is a fair question. AI summarisation is cheaper and more accessible than it has ever been. Most institutions already have survey data sitting in spreadsheets or a vendor's dashboard. On paper the maths is simple. Feed the data in, ask for themes, ship a report. The maths works for an afternoon's worth of insight. It runs out of road as soon as you try to do anything serious with it.
We have spent five years building what we now call the StudentPulse data model. Not a survey engine with AI bolted on, but a shared structure that ties together questions, student responses, and the actions staff take in response. Three million data points from hundreds of institutions across 15+ countries feed the same model.
Below, a conversation with Rune Sønderby, our Director of Product, on what survey-plus-AI actually delivers, where it falls down, and why the structural difference matters more than model quality for the kind of insight institutions need.
It gives them something. I don't want to oversell this. If you have a thousand comments and you ask a good AI tool to find themes, you will get themes back. They will look reasonable. You can ship a report.
What you won't have is comparability. The themes that come back are specific to that batch of comments. Run the same exercise next semester with a slightly different set and the themes will look different, even when students are saying the same things. Run it at another institution and the themes will be different again. You cannot aggregate. You cannot track change over time with confidence. You cannot see whether what worked at one school helps another.
That is not a limitation of the AI. It is a limitation of starting from comments and inferring structure on the fly, rather than placing comments into a structure that already exists.
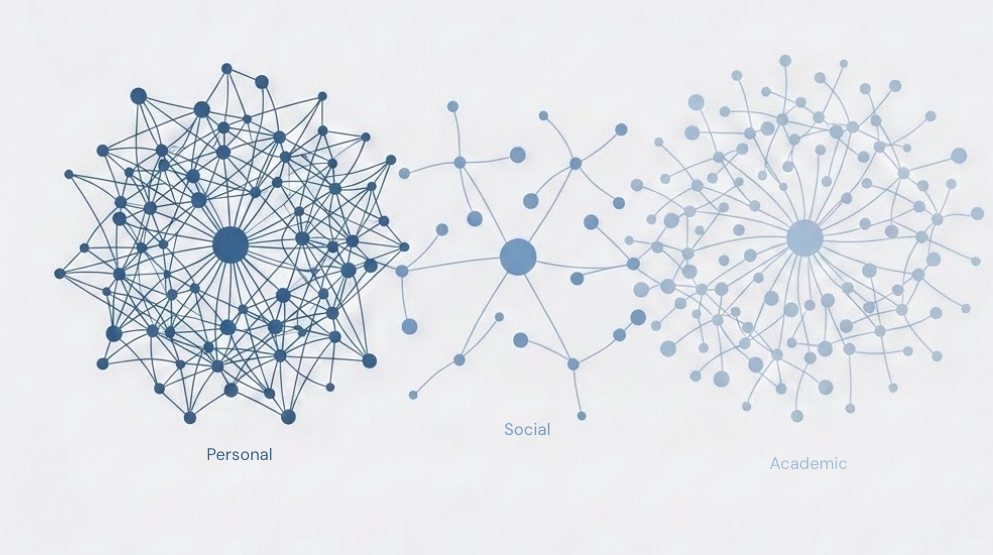
We organise everything into three levels. Domains, topics, and subtopics. There are three domains: personal, social and academic. The research underneath that split is well-established. Each domain holds around ten topics. Each topic holds a set of subtopics.
Every question we offer and every comment a student writes gets placed somewhere in that hierarchy. A student writing about workload pressure ends up in workload pressure. A question about learning goals lives under learning goals and outcomes. The actions staff can take are tagged to the same topics. So when we say “a topic,” we mean something specific. A set of questions, a set of student responses, and the actions tried in response. Tied together.
Two institutions can ask different questions and feed the same topic. One asks, “Are the learning goals of this course clear to me?” Another asks, “I know what to do to succeed with this course.” Different sentences. Same topic. That is what makes the data comparable across the platform.
A single institution sitting on its own survey data has a small picture. Even a large university might have ten thousand responses on a given topic, which sounds like a lot until you try to find a pattern robust enough to act on.
When you have hundreds of institutions feeding the same structure, the question changes. You are not asking what students at this school think about workload. You are asking what we have learned about workload from millions of student responses, and which of the actions tried across the network actually helped students, and which did not.
That is the 1 plus 1 isn't 2 part. The value is not additive. Once the structure is shared, the data compounds.
More. This is the part that survey tools don't have, even good ones.
Three things flow into the same structure. The questions we ask. The responses students give, including scores, sentiment, and free-text comments. And the actions taken in response: self-help resources, one-to-one routing, and the staff actions that follow.
All three are tagged to the same topics. So we can see not just what students are saying, but which actions improved the score on that topic over time. That feedback loop is what makes recommendations get sharper as the platform is used. Without that loop, you are guessing.
Anonymity is preserved at every step. Nothing about a specific student or institution moves across the network. What moves is patterns: this kind of action helped on this kind of topic in this kind of context. That is the recommendation engine.
It matters because institutions are rightly careful about what gets shared. Nothing about their students, their results, or their internal actions is identifiable outside their own dashboard. The intelligence comes from structure, not from data sharing.
Survey tools and AI summaries are useful. They are not what we are. The question I would ask anyone evaluating platforms in this space is: what is the structure underneath this? Because if there is no shared structure, every report you generate is one-off. Every recommendation is locally invented. Every improvement story has to be rebuilt from scratch.
If the structure is there, the work compounds. That is the difference. The StudentPulse data model is the foundation underneath every check-in, summary, and recommendation we deliver.




